

集成学习是一种通过组合多个模子来提高推断性能的机器学习行为。它通过将多个弱学习器的成果联结起来,变成一个强学习器,从而培植模子的准确性和持重性。立地丛林(Random Forest)是集成学习中一种卓越流行且有用的算法,卓越适用于分类和追思任务。本文将珍视先容Python中怎样使用立地丛林算法进行数据分析,并联结具体的代码示例,展示其愚弄场景和上风。
集成学习的基本宗旨
集成学习是指将多个基模子(每每称为弱学习器)组合起来,以构建一个更强的模子。集成学习的念念想开始于“群体贤慧”,即通过集体有缱绻来弥补单个模子的不及。集成学习主要分为两类:Bagging和Boosting。
Bagging(Bootstrap Aggregating)
Bagging是一种并行集成行为,它通过在测验集上屡次有放回地抽样生成多个子集,并在每个子集上测验基模子。最终成果通过对扫数基模子的推断成果进行平均(关于追思任务)或投票(关于分类任务)来赢得。立地丛林即是Bagging的一个典型代表。
Boosting
Boosting是一种功令集成行为,它通过握住退换样本的权重,使得每个新的基模子愈加和顺前一个模子罪状分类的样本。与Bagging不同,Boosting的基模子是挨次构建的,每个新模子齐会试图改动前一个模子的罪状。
立地丛林算法
立地丛林是Bagging的一个特例,它由多个有缱绻树模子构成。每个有缱绻树齐是在一个立地样本上测验的,何况在每个节点处,立地继承一部分特征进行分裂。通过这种花式,立地丛林简略减少模子的方差,从而提高推断的准确性和持重性。
立地丛林的优点
高准确性:通过组合多个有缱绻树,立地丛林每每比单个有缱绻树有更好的推断性能。
抗过拟合:立地丛林通过在测验时引入立地性,有用地裁汰了过拟合的风险。
搞定高维数据:立地丛林简略很好地搞定高维数据,何况不需要进行特征继承。
持重性:立地丛林对噪声和格外值具有较高的鲁棒性。
使用立地丛林进行分类
底下的示例展示了怎样使用Python的scikit-learn库已毕立地丛林分类。
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_score# 加载数据集iris = load_irisX = iris.datay = iris.target# 分辨测验集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 运行化立地丛林分类器rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)# 测验模子rf_classifier.fit(X_train, y_train)# 推断测试集y_pred = rf_classifier.predict(X_test)# 筹画准确率accuracy = accuracy_score(y_test, y_pred)print(f"立地丛林分类器的准确率: {accuracy:.2f}") # 立地丛林分类器的准确率: 1.00
在这个示例中,使用scikit-learn库中的RandomForestClassifier对Iris数据集进行了分类。模子在测试集上的推断准确率涌现了立地丛林的有用性。
使用立地丛林进行追思
立地丛林通常适用于追思任务。以下示例展示了怎样使用立地丛林进行房价推断。
from sklearn.datasets import fetch_california_housingfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error# 加载数据集california_housing = fetch_california_housingX = california_housing.datay = california_housing.target# 分辨测验集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 运行化立地丛林追思器rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)# 测验模子rf_regressor.fit(X_train, y_train)# 推断测试集y_pred = rf_regressor.predict(X_test)# 筹画均方盘曲mse = mean_squared_error(y_test, y_pred)print(f"立地丛林追思器的均方盘曲: {mse:.2f}") # 立地丛林追思器的均方盘曲: 0.26
在这个示例中,使用RandomForestRegressor对波士顿房价数据集进行了追思分析。通过筹画均方盘曲(MSE),不错评估模子的推断性能。
立地丛林的伏击参数
n_estimators:丛林中树的数目。树的数目越多,模子的清爽性越好,但筹画支出也会增多。
max_depth:每棵树的最大深度。截止树的深度不错幸免过拟合。
min_samples_split:里面节点再分辨所需的最小样本数。这个参数影响树的滋长。
min_samples_leaf:叶子节点所需的最小样本数。不错幸免树过于滋长。
max_features:用于分裂的最大特征数。减少特征数目不错裁汰模子的方差。
退换超参数的示例
为了赢得更好的模子性能,不错通过网格搜索(Grid Search)来退换立地丛林的超参数。
from sklearn.datasets import fetch_california_housingfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.model_selection import GridSearchCV, train_test_split# 加载数据集california_housing = fetch_california_housingX = california_housing.datay = california_housing.target# 分辨测验集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 界说参数网格param_grid = { 'n_estimators': [100, 200, 300], 'max_depth': [None, 10, 20, 30], 'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 2, 4], 'max_features': ['auto', 'sqrt'] # 这些在RandomForestRegressor中是有用的}# 运行化立地丛林追思器rf_regressor = RandomForestRegressor(random_state=42)# 使用网格搜索退换参数grid_search = GridSearchCV(estimator=rf_regressor, param_grid=param_grid, cv=5, n_jobs=-1, verbose=2, error_score='raise')grid_search.fit(X_train, y_train)# 输出最好参数print(f"最好参数: {grid_search.best_params_}") # 最好参数: {'max_depth': None, 'max_features': 'sqrt', 'min_samples_leaf': 1, 'min_samples_split': 2, 'n_estimators': 300}
在这个示例中,使用了网格搜索来自动退换立地丛林的超参数,以赢得更好的模子性能。
立地丛林的可解说性
尽管立地丛林本体上是一个“黑箱”模子,但仍然不错通过一些行为来提高其可解说性。举例,特征伏击性(Feature Importance)是立地丛林中一个卓越有用的宗旨,它简略告诉咱们每个特征在模子有缱绻中的伏击进程。
索要特征伏击性
import matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_irisX = iris.datay = iris.target# 分辨测验集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 运行化立地丛林分类器rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)# 测验模子rf_classifier.fit(X_train, y_train)# 索要特征伏击性importances = rf_classifier.feature_importances_# 可视化特征伏击性plt.figure(figsize=(10, 6))plt.barh(iris.feature_names, importances, align='center')plt.xlabel('Feature Importance')plt.title('Feature Importance in Random Forest')plt.show
输出成果:
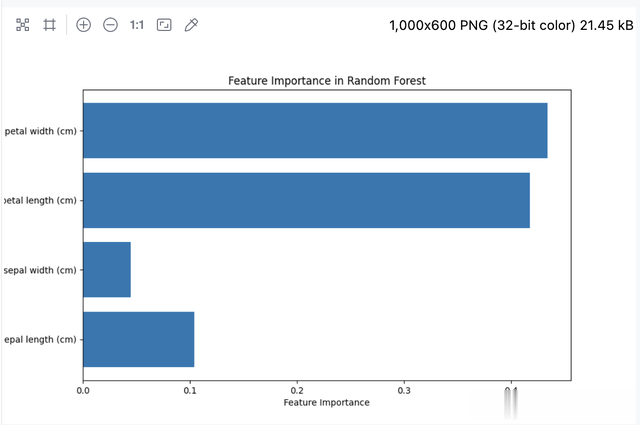
通过这个示例,不错可视化各个特征在立地丛林中的伏击性,从而匡助咱们勾搭模子的有缱绻经由。
总结
立地丛林是集成学习中的一种繁密算法,具有高准确性、抗过拟合、搞定高维数据和持重性的优点。本文珍视先容了如安在Python中使用立地丛林进行分类和追思任务,并商讨了怎样退换超参数以培植模子性能。通过特征伏击性分析,还不错增多模子的可解说性。立地丛林在践诺愚弄中粗鄙使用,掌捏这一算法将权臣培植你的数据分析和建模材干。